
Superescalar
Este artigo não cita fontes confiáveis. (Fevereiro de 2019) |

Processadores superescalares exploram paralelismo em nível de instruções de maneira a capacitar a execução de mais de uma instrução por ciclo de clock. Este tipo de processador decodifica múltiplas instruções de uma vez e o resultado de instruções de desvio condicional são geralmente preditas antecipadamente, durante a fase de busca, para assegurar um fluxo ininterrupto.
Arquitetura Superescalar[editar | editar código-fonte]
Na arquitetura superescalar, várias instruções podem ser iniciadas simultaneamente e executadas independentemente umas das outras. A arquitetura pipeline permite que diversas instruções sejam executadas ao mesmo tempo, desde que estejam em estágios diferentes do pipeline.
As arquiteturas superescalares incluem todos os aspectos do pipeline e ainda acrescentam o fato de as instruções poderem estar executando no mesmo estágio do pipelining (em linhas pipelining diferentes). Assim, elas têm a habilidade de iniciarem múltiplas instruções no mesmo ciclo de clock. A forma como estão dispostas e utilizadas as estruturas e os componentes do processador define o modelo da arquitetura de um processador. Há diversas classificações de arquiteturas de processadores baseadas nas suas políticas e nos caminhos de execução dos dados.
Uma arquitetura superescalar deve possuir uma série de componentes especiais para executar mais de uma instrução por ciclo:
- Unidade de Busca de Instruções: capaz de buscar mais de uma instrução por ciclo. Possui também um preditor de desvios, que deve ter alta taxa de acerto, para poder buscar as instruções sem ter que esperar pelo resultados dos desvios.
- Unidade de Decodificação: capaz de ler vários operandos do banco de registradores a cada ciclo. Note que cada instrução sendo decodificada pode ler até dois operandos do banco de registradores.
- Unidades Funcionais Inteiras e de Ponto Flutuante: em número suficiente para executar as diversas instruções buscadas e decodificadas a cada ciclo.
Superescalar x superpipeline[editar | editar código-fonte]
Uma técnica alternativa para atingir alta performance no processamento é intitulada como superpipelined - termo utilizado pela primeira vez em 1988. Essa técnica explora o fato de que o estágio de pipeline executa tarefas que requerem menos de meio ciclo de clock. Assim, um processador com velocidade de clock interno dobrada, permite um aumento de performance de duas tarefas executadas em um único ciclo de clock externo.
Por exemplo: Uma máquina usando pipeline básico executa uma instrução por ciclo de clock e tem e um estágio de pipeline por clock também. O pipeline tem quatro estágios: busca, decodificação, execução e armazenamento do resultado. Ainda que várias instruções sejam executadas concorrentemente, apenas uma instrução encontra-se na fase de execução.
A implementação superpipelined é capaz de executar duas fases da pipeline de cada vez. Um forma alternativa de observa-lo passa por perceber que as instruções executadas em cada fase podem ser divididas em duas partes, não sobrepostas, onde cada fase é executada em meio ciclo de clock. Uma implementação superpipelined com este comportamento denomina-se de grau 2. Esta imagem retrata bem as diferenças entre as duas implementações mencionadas.
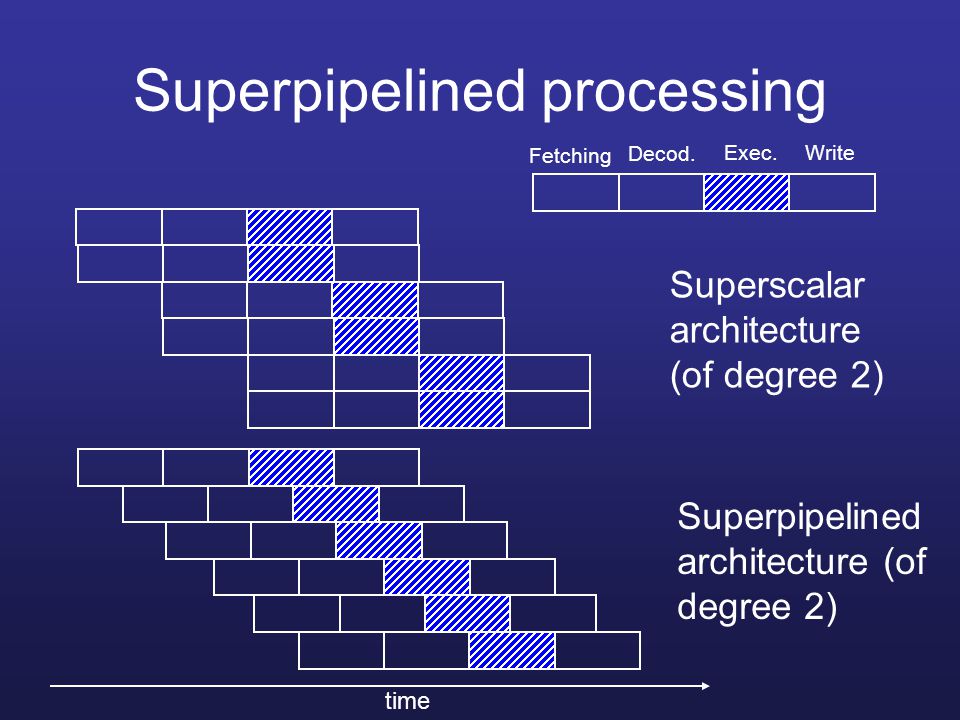{kind=link}
A implementação superescalar pode executar duas instruções em paralelo, devido ao facto de existirem duas fases homólogas.
Ambas as implementações possuem o mesmo número de instruções executadas ao mesmo tempo, no mesmo estado.
Limitações[editar | editar código-fonte]
A abordagem superescalar depende da habilidade de executar várias instruções em paralelo. O termo paralelismo no nível de instruções diz respeito ao nível no qual as instruções de um programa podem ser executadas de forma paralela (em média).
Dependência de dados verdadeira (true data dependency)[editar | editar código-fonte]
Considere a seguinte seqüência de instruções:
add r1, r2 # carregar registrador r1 com a soma dos conteúdos de r1 e r2
move r1, r3 # carregar registrador r3 com o conteúdo de r1
A segunda instrução pode ser buscada e decodificada antecipadamente, mas não pode ser executada até que seja completada a execução da primeira instrução. A razão é que ela depende do dado produzido pela primeira. Essa situação é denominada como dependência de dados verdadeira (também chamada de dependência de fluxo ou dependência de escrita-leitura).
Dependência de desvios[editar | editar código-fonte]
A presença de desvios condicionais em uma seqüência de instruções complica a operação do pipeline. A instrução seguinte a um desvio condicional (tomado ou não) depende dessa instrução de desvio. Esse tipo de dependência também afeta uma pipeline escalar, mas a conseqüência desse tipo de dependência é mais severa em uma pipeline superescalar, porque o número de instruções perdidas em cada atraso é maior. Se forem usadas instruções de tamanho variável, surge ainda um outro tipo de dependência. Como o tamanho de uma instrução particular não é conhecido, uma instrução deve ser decodificada, pelo menos parcialmente, antes que a instrução seguinte possa ser buscada. Isso impede a busca simultânea de instruções, requerida em uma pipeline superescalar. Essa é uma das razões pelas quais técnicas supersescalares são mais diretamente aplicáveis a arquiteturas RISC ou do tipo RISC, que possuem instruções de tamanho fixo.
Conflito de recursos[editar | editar código-fonte]
Um conflito de recurso ocorre quando duas ou mais instruções competem, ao mesmo tempo, por um mesmo recurso. Exemplos de recursos incluem memórias, caches, barramentos, portas de bancos de registradores e unidades funcionais (por exemplo, o somador da ULA). Em termos de pipeline, um conflito de recurso apresenta um comportamento semelhante ao de uma dependência de dados. Existem, entretanto, algumas diferenças. Por um lado, conflitos de recursos podem ser superados pela duplicação de recursos, enquanto uma dependência de dados não pode ser eliminada. Além disso, quando uma operação efetuada em uma dada unidade funcional consome muito tempo para ser completada, é possível minimizar os conflitos de uso dessa unidade por meio de sua implementação como uma pipeline.